اسلایدها و ویدیوهای درس یادگیری ماشین

دوره آموزش پایتون و پیادهسازی جویشگر متنی
مهر ۲۲, ۱۳۹۶
اسلایدها و ویدیوهای درس هوش مصنوعی
مهر ۲۳, ۱۳۹۶
توجه: اسلایدها و ویدیوهای بهروز شده این درس ازصفحه زیر در دسترس است.
یادگیری ماشین یکی از مهمترین دروس رشته هوش مصنوعی در دوره کارشناسی ارشد و پایه بسیاری از دروس دیگر مانند بازشناسی الگو، پردازش تصویر، بینایی ماشین، پردازش زبان طبیعی و پردازش گفتار است. شما در درس یادگیری ماشین با مفاهیم پایه و برخی از مهمترین روشها و الگوریتمهای یادگیری ماشین آشنا میشوید. برخی از روشهایی که در این درس به آنها خواهیم پرداخت عبارتند از: رگرسیون، رگرسیون لجستیک، شبکههای عصبی، ماشینهای بردار پشتیبان، خوشهبندی، کاهش ابعاد و تحلیل مؤلفههای اصلی، سامانههای توصیهگر و تشخیص آنومالی.
اسلایدهای یادگیری ماشین
- معرفی: (دانلود)
یادگیری نظارت شده
- رگرسیون: (دانلود)
- خودآموز متلب: (دانلود)
- دستهبندی و رگرسیون لجستیک: (دانلود)
- رگرسیون لجستیک
- رگرسیون لجستیک چندکلاسی
- روشهای بهینهسازی پیشرفته در متلب
- رگولاریزاسیون یا تنطیم: (دانلود)
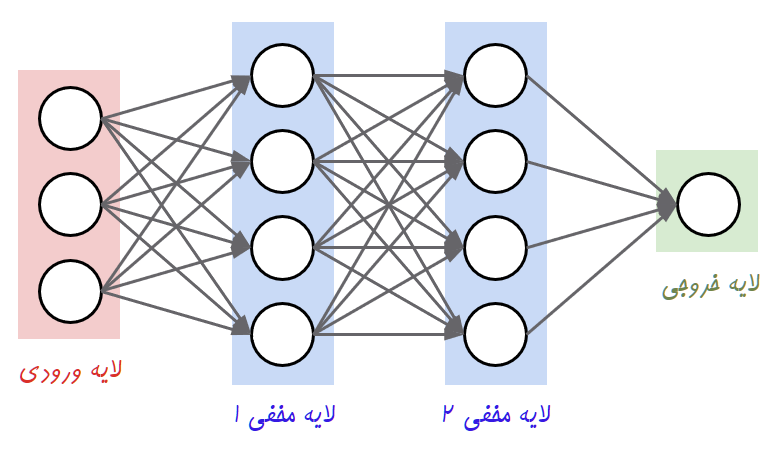
- شبکههای عصبی: (دانلود)
- آموزش شبکههای عصبی: (ادانلود)
- اشکالزدایی سیستمهای یادگیری ماشین: (دانلود)
- طراحی یک سیستم یادگیری ماشین: (دانلود)
- ماشینهای بردار پشتیبان: (دانلود)
یادگیری بدون نظارت
- یادگیری بدون نظارت و خوشهبندی: (دانلود)
- کاهش ابعاد و فشردهسازی: (دانلود)
- سیستمهای توصیهگر: (دانلود)
- تشخیص آنومالی: (دانلود)
مشاهده ویدیوها
پروژههای پیادهسازی در متلب
- پروژه ۱. پیادهسازی رگرسیون خطی تک متغیره و چند متغیره، الگوریتم گرادیان کاهشی، نرمالسازی ویژگیها و معادلات نرمال در متلب (اکتاو)
[pdfviewer]http://www.snrazavi.ir/wp-content/uploads/2017/10/ex1.pdf[/pdfviewer]
- پروژه ۲. پیادهسازی الگوریتم کلاسبندی رگرسیون لجستیک و تنظیم برای برخورد با بیشبرازش
[pdfviewer]http://www.snrazavi.ir/wp-content/uploads/2017/10/ex2.pdf[/pdfviewer]
- پروژه ۳. پیادهسازی الگوریتم رگرسیون لجستیک چند کلاسی و شبکههای عصبی
[pdfviewer]http://www.snrazavi.ir/wp-content/uploads/2017/10/ex3.pdf[/pdfviewer]
پیشنیازها
- آشنایی با یک زبان برنامهنویسی، ترجیحا پایتون یا متلب (ویدیوهای مربوط به دوره آموزش پایتون)
- آشنایی با مباحث تحلیل و طراحی الگوریتمها (اسلایدهای درس تحلیل و طراحی الگوریتمها)
- آشنایی اولیه با جبر خطی (معرفی جبر خطی) (ویدیوهای بسیار مفید جبر خطی از خان آکادمی)
- مفاهیمی مانند ماتریس و بردار، عملیات ماتریسی، وارون، دترمینان، حل یک دستگاه معادلات خطی
- آشنایی با احتمالات مهندسی (اسلایدهای معرفی احتمالات از درس هوش مصنوعی)
- آشنایی با حساب دیفرانسیل و انتگرال (ویدیوهای مفید درباره حساب چند متغیره از خان آکادمی)
مراجع و منابع
- «یادگیری ماشین: یک دیدگاه احتمالاتی»؛ کوین مورفی، ۲۰۱۲

- «آشنایی با یادگیری ماشین»؛ ادهم آلپایدین، ویراست سوم، ۲۰۱۴

- «بازشناسی الگو و یادگیری ماشین»؛ کریستوفر بیشاپ، ۲۰۰۶

- کلاس یادگیری ماشین، دانشگاه استنفورد، اندرو اینگ، ۲۰۱۷
ویدیوهای مرتبط
- «کارگاه یادگیری ماشین با پایتون» (ویدیوها)
- «کارگاه برنامهنویسی پایتون» (ویدیوها)
- «دوره پاییزه یادگیری عمیق در پژوهشگاه ارتباطات و فناوری اطلاعات: روز دوم» (ویدیوها و اسلایدها)


37 ديدگاه
بسم تعالی !
خوشحالم که به عنوان اولین دیدگاه در بخش “یادگیری ماشین” واقعا ازتون تشکر کنم استاد سید ناصر رضوی !
بنده با این که دانشجو شما نبودم ولی واقعا از مطالب تون لذت بردم ، مخصوصا که همین بخش یادگیری ماشین که انصافا هیچ آموزش مفیدی به زبان فارسی و ۱۰۰ % رایگان تا به امروز ندیده بودم که خوش بختانه یک عزیزی آدرس کانال یوتیوب شما رو داد و آموزش هاتون رو دیدم و همشون رو دانلود کردم و با اشتیاق نگاه کردم ! واقعا خوب تدریس کردید مخصوصا بخش یادگیری ماشین ، قسمت اول که تازه الان دیدمش !
امیدوارم همین طوری تا آخر پیش برید ، واقعا ممنونم ازتون.
با سلام. بسیار سپاسگزارم.
با سلام
استاد میتونیم آدرس وب سایتتونو به دانشجوهای سایر دانشگاه معرفی کنیم تا از مطالبش استفاده کنن؟
با تشکر از زحماتتون
با درود
اگر منظورتون همین سایت شخصی بنده است، بله قطعا. اصلا هدف همینه. بسیار سپاسگزار خواهم بود اگر زحمت این کار رو بکشید.
اما پیازا تنها برای استفاده دانشجویان همون درس و دوره است.
با سلام و عرض احترام خدمت استاد محترم جناب آقای دکتر رضوی
من ویدئوهای رگرسیون لجستیک و رگرسیون لجستیک چندکلاسی رو دیدم واقعا عالی بودند و خیلی خوشحالم که این ویدئوها زمانی دردسترس قرار گرفتند که در آستانه کنکور هستم و مسلما کمک زیادی به من خواهند کرد.
امیدوارم ویدئوهای قسمتهای بعدی هم دردسترس قرار بگیرند تا کسانی که نیاز دارند به راحتی بتوانند استفاده کنند و واقعا جای تشکر فراوان دارد که این سایت رو راه اندازی کردید و اسلایدها و ویدئوها رو در دسترس عموم قرار دادید.
با تشکر از زحمات شما
با درود. سپاسگزارم. براتون آرزوی موفقیت میکنم.
با سلام یک دنیا ممنون بابت این آموزش ها،به شخصه برای من خیلی مفید بودن و خیلیییییییییی کاربردی بودن.
می خواستم ببینم برای سیستم های توصیه گر هم آموزش ویدیویی وجود داره ممنون میشم اگر داره اونم در اختیارمون بزارید
بازم ممنون
با درود و سپاس. بسیار خوشحالم که مطالب براتون مفید بوده.
ویدیوها به تدریج ضبط میشوند و هر ویدیو به محض آماده شدن در وبسایت و یوتیوب قرار خواهد گرفت.
با آرزوی شادکامی
ممنون استاد.
استاد چجوری میشه باهاتون در تماس بود هیچ جای سایت نشانه ای از ایمیل نیست
n.razavi@tabrizu.ac.ir
خیلی ممنون بابت آموزشهایی که میزارید. خیلی عالی تدریس میکنید.
بسیار سپاسگزارم.
[…] آشنایی با روشهای یادگیری ماشینی. (اسلایدهای درس یادگیری ماشین و کارگاه یادگیری ماشین) […]
[…] یادگیری ماشین؛ سید ناصر رضوی؛ دانشکده مهندسی برق و کامپیوتر دانشگاه تبریز (پاییز ۱۳۹۶) […]
[…] یادگیری ماشین؛ سید ناصر رضوی؛ دانشکده مهندسی برق و کامپیوتر دانشگاه تبریز (پاییز ۱۳۹۶) […]
واییییی خیلی خوبه این اموزش ها ممنونم
سپاسگزارم
استاد توی اسلاید های سیستمهای توصیه گرجواب این سوال توی اسلاید ها نیست! که k رو چه مقداری باید بگیریم، ممنون میشم به این سوالمپاسخ بدید
با درود.
منظورتون از k دقیقا چیست؟ لطفا شماره اسلاید مورد نظر را بفرمایید.
اسلاید شماره ۱۰، منظورم تعداد همسایه های نزدیک هست ! سوال خود اسلاید هم هست!
بهترین k ،یا تعداد همسایه های نزدیک کمیتونیم بگیریم چند هست؟!
در پایین اسلاید ۱۸ به یک مقاله ارجاع دادهام (هرلاکر، ۲۰۰۲) که مقدار مناسب را بین ۲۰ تا ۵۰ توصیه کرده است.
اما اینها فقط پیشنهاد هستند و تعداد همسایهها میتونه کمتر یا بیشتر از مقادیر هم بشه. بهترین راه برای تعیین دقیق مقدار این گونه «ابرپارامترها» همیشه استفاده از cross-validation است.
از اینکه پاسخ دادین سپاسگذارم، سوال دیگه همکه داشتم این هست که برای چه تعداد کاربر الگوریتم نزدیک ترین همسایه ها اعمال میشود ؟ یعنی اینکه من در مقیاس خیلی بزرگی کاربر دارم ،همه این کاربران باهم به الگوریتم knn داده میشن؟؟ و یا اینکه دسته دسته می شوند و الگوریتم روی اون ها اعمال میشه؟؟ و اینکه اگر برای مثال دسته دسته شدند، و روی یک یا دو دسته اعمال کردیم، حالا اگر ۵۰ تا از نزدیکترین ها پیدا شدند دیگه عملیات روی دسته های دیگر رومتوقف می کنیم؟؟
من مقیاس کاربران شما رو نمیدونم ولی اگر تعداد کاربرهاتون خیلی زیاده، پیشنهاد میکنم روشهای مبتنی بر مدل را آزمایش کنید. یعنی برای هر کاربر و هر کالا یک مجموعه از وزنها محاسبه میشه و این باعث میشه پیشنهاد دادن خیلی سریعتر انجام بشه. الیته تو این روش هر چند وقت یک بار باید دوباره وزنها آموزش داده شوند و این فاصله زمانی بین آموزش مجدد بستگی به پویایی سیستم شما داره. هرچه سیستم شما پویاتر باشه (مدام کاربران و کالاهای جدید اضافه بشه و مدام به کالاها امتیاز داده بشه)، به روزرسانی باید زودتر انجام بشه و این آموزش مجدد میتونه خیلی زمانبر باشه، اما در پشت صحنه اجرا میشه. الگوریتم نزدیکترین همسایه در مقیاس بزرگ عملکرد بسیار کندی در زمان اجرا داره.
با سلام و خسته نباشید. بسیار ممنونم استاد بابت این ویدئو های عالی چون ما میتونیم برای آمادگی درکلاس و یا مرور مطالب به راحتی به این ویدئو ها بارها و بارها رجوع کنیم و مشکلاتمون رو برطرف کنیم . از زمانی که درجهت آموزش ما حتی درزمانی که در کلاس نیستیم صرف میکنید بسیار ممنونم با اجازتون من هم به چند نفر از دوستانم پیشنهاد کردم استفاده از سایت و فیلم های مفیدتون رو.
با درود. بسیار سپاسگزارم از محبتتون.
با سلام، و تشکرفراوان،استاد من درس های مربوط به رگرسیون را دیدم، سوالی که برام پیش اومده این هست که چرا به جای لاجستیک ( که تو این روش مجبوریم از رگرسون خطی استفاده کنیم بعدش بیایم سیگموید بگیریم )از یک کلاس بندی سنتی یا روش هایی مثل درخت تصمیم و svm استفاده نکنیم؟؟ چه مزیتی داره این روش؟؟ چه نیازی بوده که این بحث مطرح شده؟؟
با درود و سپاس. رگرسیون لجستیک خودش به تنهایی روش قدرتمندی هست و در صورت استفاده از ویژگیهای مرتبه بالاتر میتونه دستهبندی غیر خطی هم انجام بده. اما دلیل اصلی مطرح شدنش اینه که میتونیم تعدادی رگرسیون لجستیک رو به هم وصل کنیم و شبکههای عصبی ایجاد کنیم که قدرتمندترین روشها برای حل بسیاری از مسائل دستهبندی به ویژه مسائل پیچیده مثل بینایی ماشین و پردازش زبان طبیعی به شمار میروند.
درود بر شما،منظور از وصل کردن چیست؟
یعنی این که خروجی یک یا چند واحد رگرسیون لجستیک به عنوان ورودی به تعدادی رگرسیون لجستیک دیگه داده بشه که خود اونها دوباره ممکنه خروجیشون به عنوان ورودی به تعدادی رگرسیون لجستیک دیگه داده بشه و همین طور الی آخر؛ یعنی دقیقا شبکهای از دستهبندهای رگرسیون لجستیک یا همون شبکههای عصبی.
با سلام خدمت استاد
در SVM چگونه می توان بوسیله متلب accuracy را مشخص کرد ایا تدریسی یا درسی در این مورد وجود دارد.
با تشکر
با درود. دقیقا متوجه پرسش شما نشدم. معیار دقت مستقل از الگوریتم دستهبندی هست.
با سلام و سپاس
استاد می خواستم ببتیم تابع پیرسون چه بر تری نسیبت به بقیه توابع دارد که از ان در الگوریتم knn استفاده شده؟
lمنظورم برتری نسبت به بقیه توابع فاصله هست مثل اقلیدسی و کسینوسی
البته به این اشاره کردین که مزیتش در نظر گرفتن تنفاوت ها در عادات امتیاز دهی است و لی متوجه منظور نشدم
منظور این هست که بعضیها به طور متوسط نمرههای بهتری میدن (یعنی خوش نمره هستن) و بعضیها به طور متوسط نمرههای کتری میدن (بدنمره هستن) ولی صرفنظر از این موضوع سلیقههای یکسانی دارند. معیار پیرسون این موارد رو در نظر میگیره.
استاد عزیز جناب اقای دکتر رضوی
با سلام و عرض ادب
با تشکر از زحمات حضرتعالی برای انتشار این مجموعه گرانبها
سوالی از حضورتان داشتم که آیا فیلم مباحث درخت تصمیم و جنگل تصادفی را نیز بیان خواهید کرد ؟
با درود و سپاس.
متاسفانه این دوره خیر. اما به تدریج مطالب مربوط به اسلایدها را به صورت ویدیو ضبط و منتشر خواهم نمود. بسیار خوشحال میشم اولویتهای شما دوستان گرامی خودم رو هم بدونم.