چگونه یادگیری عمیق را عمیق یاد بگیرم؟

یادگیری عمیق: فرصتها و چالشها
آذر ۱۱, ۱۳۹۶
کارگاه یادگیری عمیق با پایتون
دی ۲۶, ۱۳۹۶
توجه: این نوشته در حال به روز رسانی است!
مقدمه
در چند سال گذشته، یادگیری ژرف یا یادگیری عمیق به یکی از جذابترین زمینههای پژوهشی تبدیل گشته و دستاوردهای بسیاری نیز در حوزههای گوناگون به دنبال داشته است. در این نوشته نکاتی چند به منظور راهنمایی افراد علاقمند به پژوهش در این حوزه بسیار جذاب ارائه میگردد. اجازه دهید این نوشته را با دو نقل قول از دو نفر از پیشگامان حوزه یادگیری ماشین و به ویژه یادگیری عمیق شروع کنیم:


یادگیری ماشین چیست؟
برای درک بهتر یادگیری عمیق، ابتدا باید درک مناسبی از یادگیری ماشینی و روشهای آن داشته باشیم.

با توجه به تعریف ارائه شده، میتوان گفت یادگیری ماشین یک «رویکرد داده-محور» به منظور حل مسائل پیچیده است. به عنوان مثال، فرض کنید میخواهیم برنامهای بنویسیم که ایمیلهای معتبر را از هرزنامهها (اسپم) تفکیک کند.
در رویکرد داده-محور به جای آنکه مجبور باشیم برای ماشین تعریف کنیم که یک ایمیل معتبر با یک هرزنامه چه تفاوتهایی دارد (مثلا از طریق نوشتن یک مجموعه بلند بالا از قوانین به کمک دستورات شرطی)، میتوانیم تعدادی نمونه از هر دو دسته جمعآوری نماییم (مجموعه آموزشی). سپس میتوانیم نمونهها را در اختیار ماشین قرار دهیم و از ماشین بخواهیم با توجه به نمونههای فراهم شده، بکوشد تفاوت میان ایمیل معتبر و هرزنامه را یاد بگیرد. این یادگیری باید به گونهای باشد که بتواند دانش یاد گرفته را برای ایمیلهای جدید نیز «تعمیم» دهد.
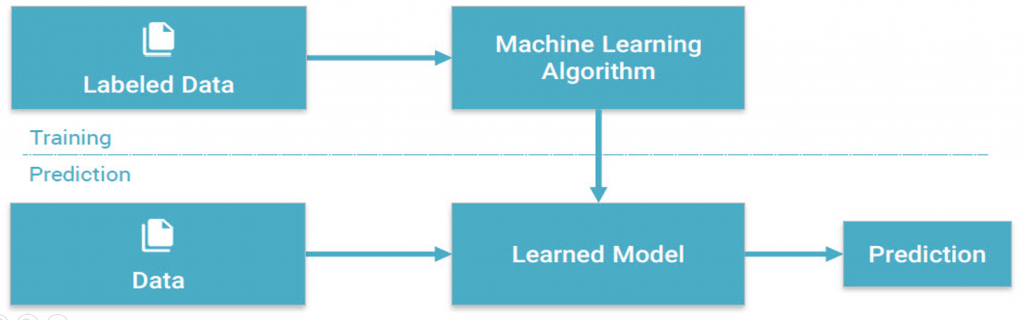
رویکردهای گوناگون یادگیری ماشین



انواع مسائل در یادگیری ماشین

تفاوت یادگیری عمیق با روشهای سنتی یادگیری ماشین
در رویکردهای سنتی یادگیری ماشین، یکی از مهمترین و زمانبرترین چالشها، استخراج ویژگیهای مناسب از دادهها است. این مرحله «مهندسی ویژگی» نام دارد. اما در یادگیری عمیق تنها کافی است تعداد بسیاری داده و زمان کافی در اختیار الگوریتم یادگیری قرار دهیم. سپس الگوریتم میتواند بهترین ویژگیهای مناسب به منظور بازنمایی دادههای مورد نظر را یاد بگیرد. از این رو، یادگیری عمیق را «یادگیری بازنمایی» نیز مینامند.


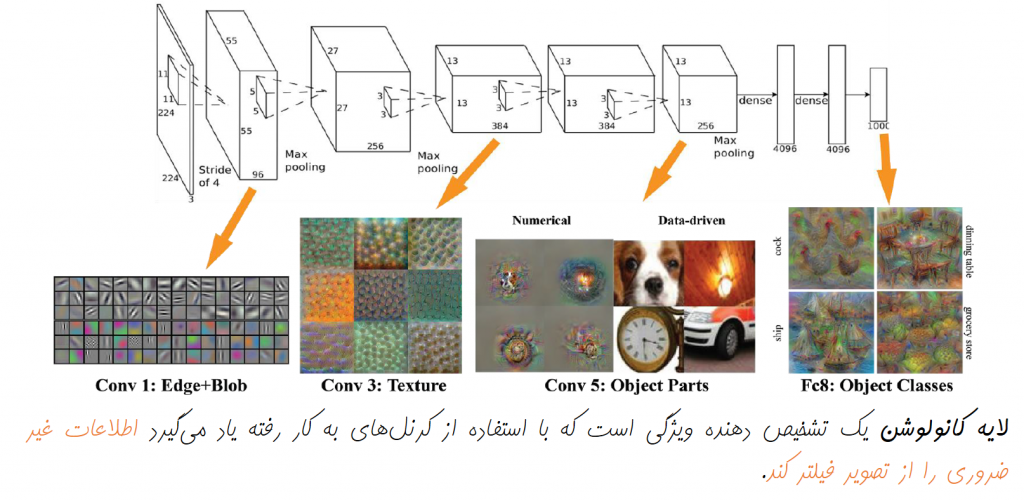
به عنوان نمونه در مورد تصاویر، هر یک از لایهها در سلسلهمراتب یادگیری عمیق، میتواند یک مجموعه جدید از ویژگیهای سطح بالاتر نسبت به لایه قبل از خود را یاد بگیرد. همانگونه که در شکل زیر مشاهده میکنید، اولین لایه مجموعهای از ویژگیهای سطح پایین در تصاویر همانند لبهها و گوشهها را یاد گرفته است. در ادامه، لایه بعدی با ترکیب این ویژگیهای سطح پایین، توانسته ویژگیهای سطح بالاتری همانند اشکال ساده هندسی، منحنیها و الگوهای ساده را یاد بگیرد و این روند در لایههای بالاتر نیز ادامه پیدا میکند.
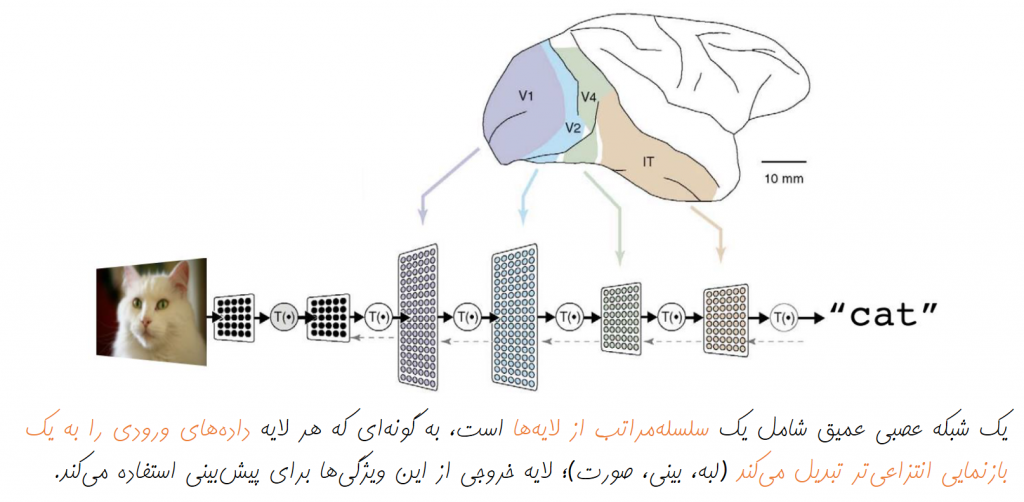
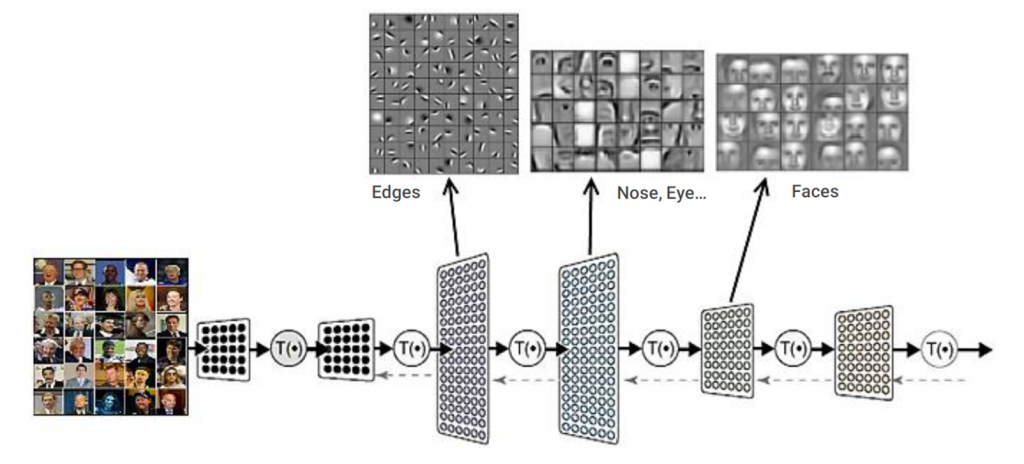
کاربردها و دستاوردها

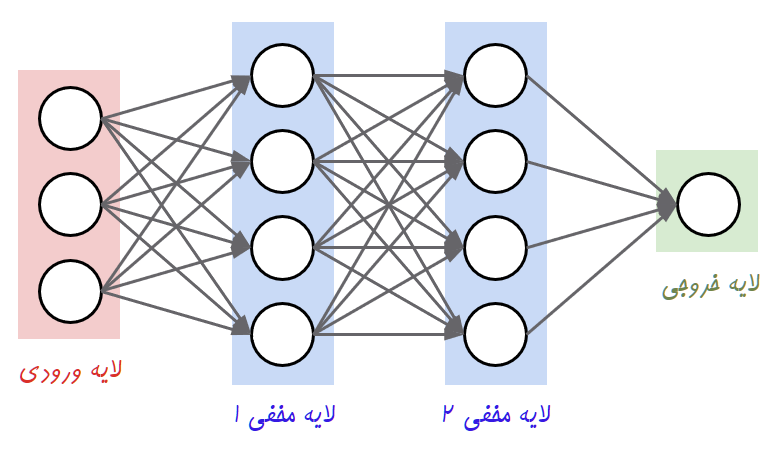
شبکههای عصبی مصنوعی
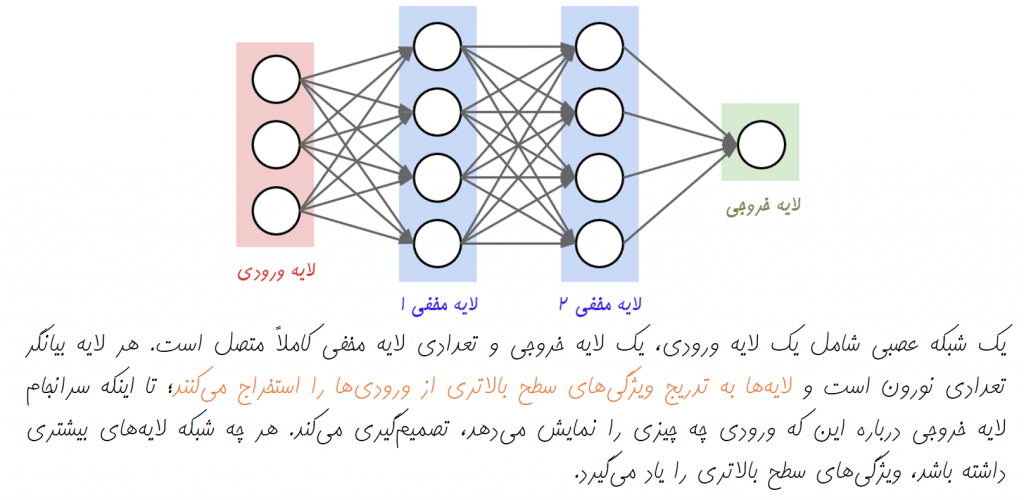
نورونها
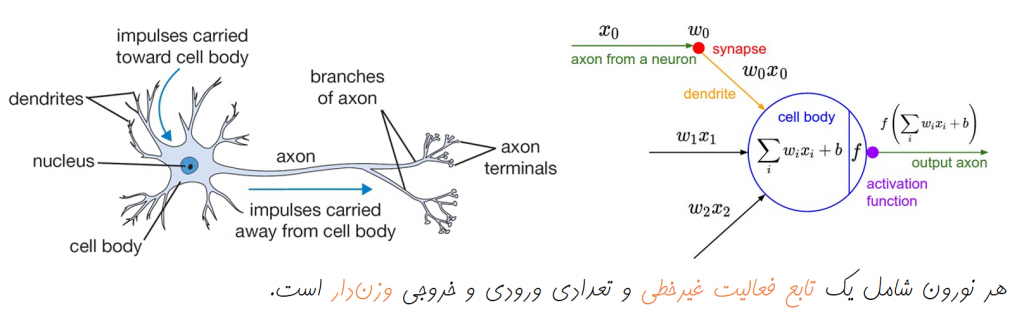
توابع فعالیت غیرخطی

آموزش شبکههای عصبی
- الگوریتم گرادیان کاهشی و پسانتشار خطا
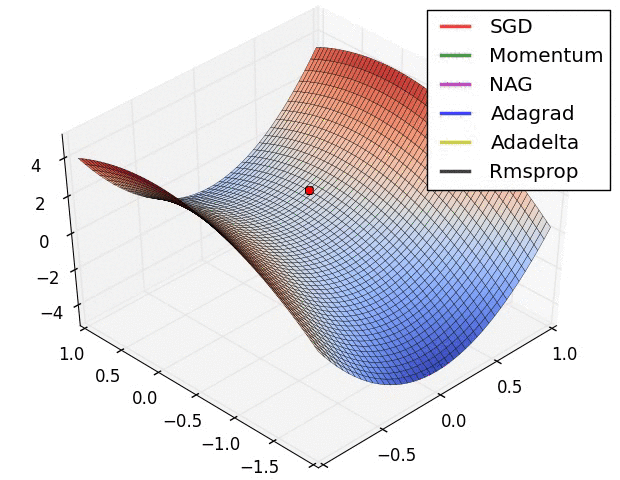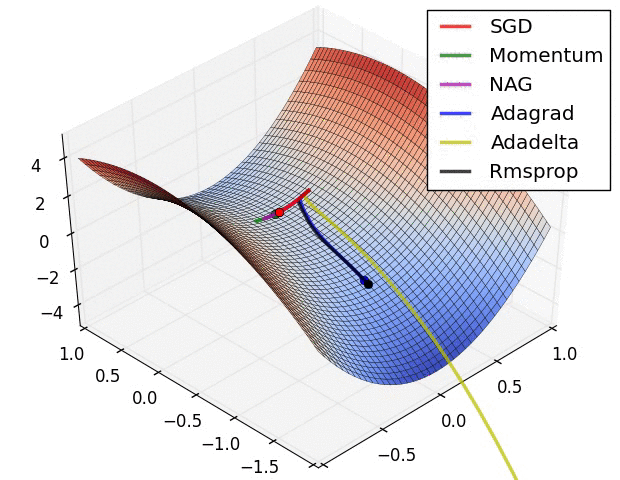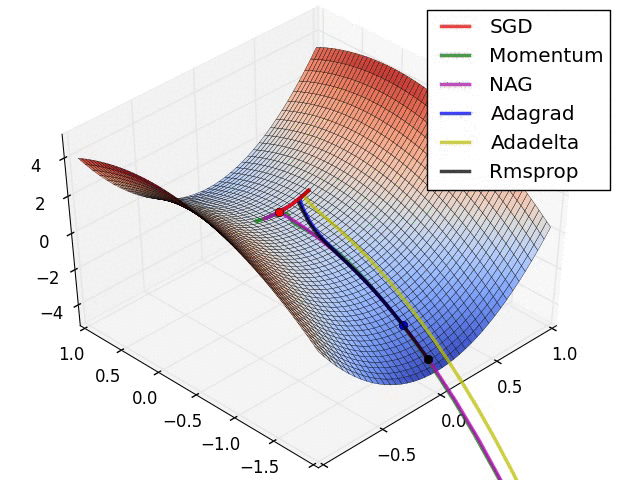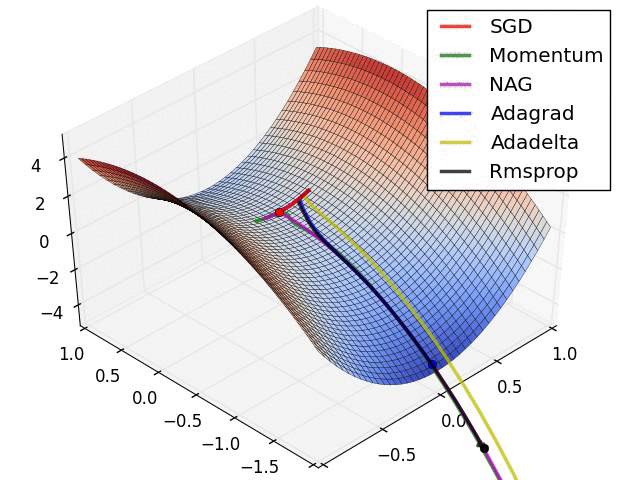
یادگیری عمیق
گونههای یادگیری عمیق
- خودرمزگذارهای عمیق: یادگیری بازنمایی، کاهش ابعاد و فشردهسازی
- شبکههای عصبی کانولوشن: پردازش تصاویر و بینایی ماشین
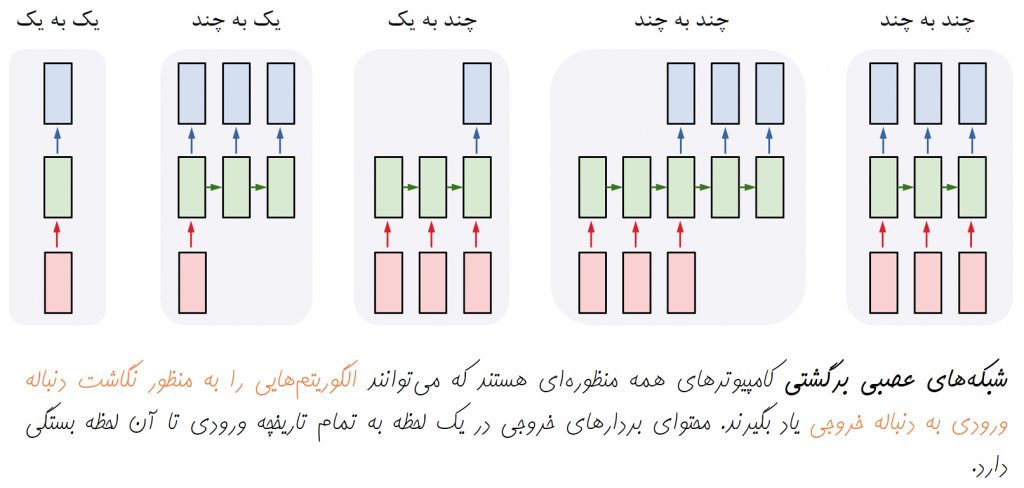
- شبکههای برگشتی: پردازش دنبالهای از دادهها همانند دادههای متنی و پردازش گفتار
- شبکههای مولد خصمانه (GANs): تولید دادههای مصنوعی
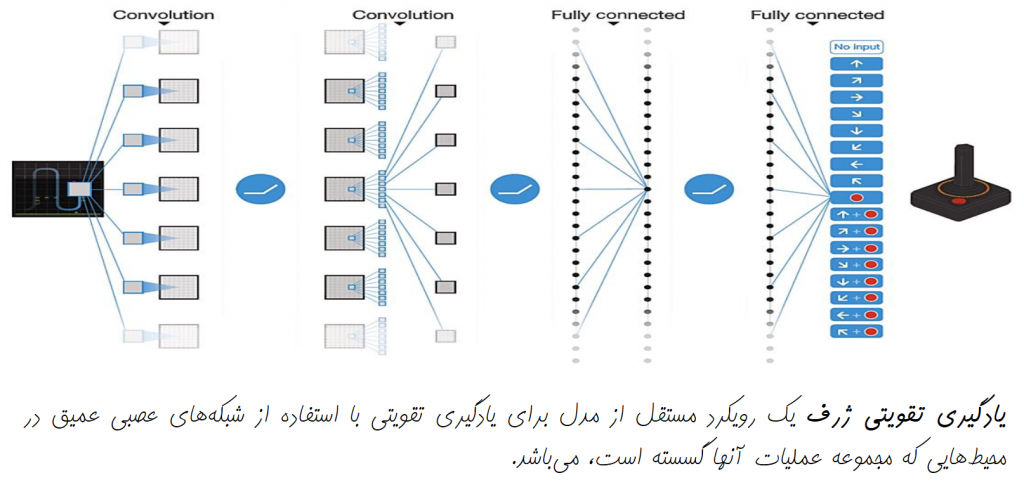
- یادگیری تقویتی عمیق: بازیهای رایانهای و روباتیک
شبکههای عصبی کانولوشنال
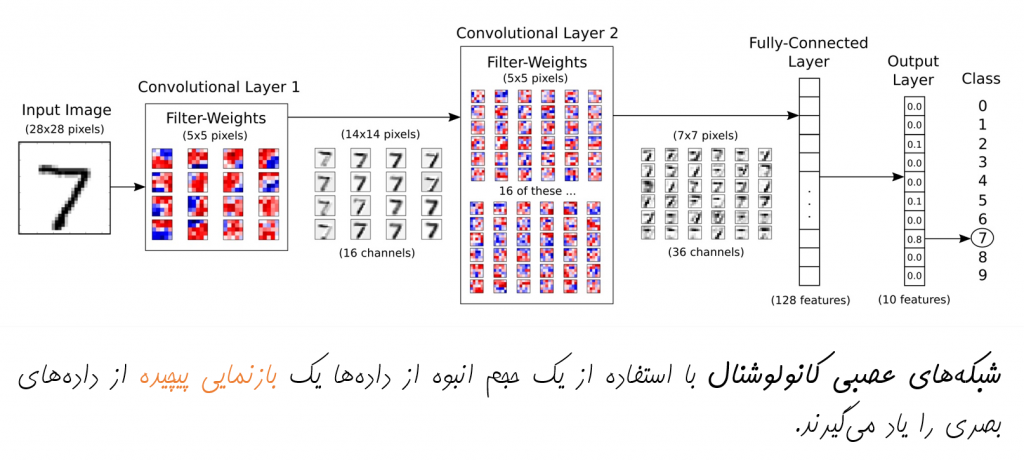
لایه کانولوشن
شبکههای برگشتی
یادگیری تقویتی عمیق
پیشنیازها
- آشنایی با مفاهیم پایه در برنامهنویسی و یک زبان برنامهنویسی
- آشنایی با روشهای تحلیل و طراحی الگوریتمها
- یادگیری ماشین
- جبر خطی (وبسایت خان آکادمی و فایل نوتبوک کتابخانه NumPy)
- حساب چند متغیره
- آمار و احتمالات
زبان برنامهنویسی
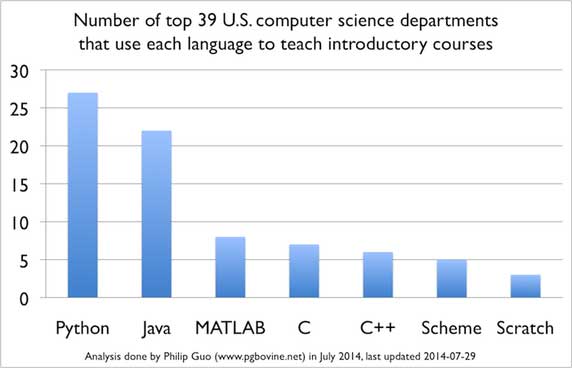
شاید یکی از اولین پرسشهایی که یک پژوهشگر در آغاز شروع به پژوهش در حوزه یادگیری ماشین و به ویژه یادگیری عمیق با آن روبهرو میشود، این است که کدام زبان برنامهنویسی برای این کار مناسبتر است. پاسخ به این پرسش تا حدودی به سلیقه شخصی افراد و پیشزمینههای آنان بستگی دارد.
میتوان گفت تمامی زبانهای سطح بالا برای این منظور قابل استفاده هستند و هر کدام نیز دارای مزایا و معایب ویژه خود هستند. اما بدون تردید زبان برنامهنویسی «پایتون» گزینه نخست بسیاری از شرکتها و پژوهشگران است. در ادامه به برخی از مهمترین دلایل این مسئله اشاره شده است:
- سادگی یادگیری
- کمینهگرایی
- توسعهپذیری با انبوهی از کتابخانههای موجود
- پشتیبانی گسترده
- وجود انبوهی از منابع و کدهای پیادهسازی شده قابل دسترس

در این راستا و به منظور یادگیری پایتون، کتاب «پایتون برای تحلیل دادهها» یکی از بهترین کتابهایی است که میتوان مطالعه نمود. این کتاب را میتوانید از اینجا مطالعه کنید.
ابزارهای لازم
برخی از مهمترین ابزارها به منظور پیادهسازی الگوریتمهای یادگیری عمیق عبارتند از:
- تنسورفلو از شرکت گوگل،
- تورچ و نسخه پایتون آن یعنی پایتورچ از شرکت فیسبوک و
- جعبه ابزار شبکههای محاسباتی یا سیانتیکی از شرکت مایکروسافت.
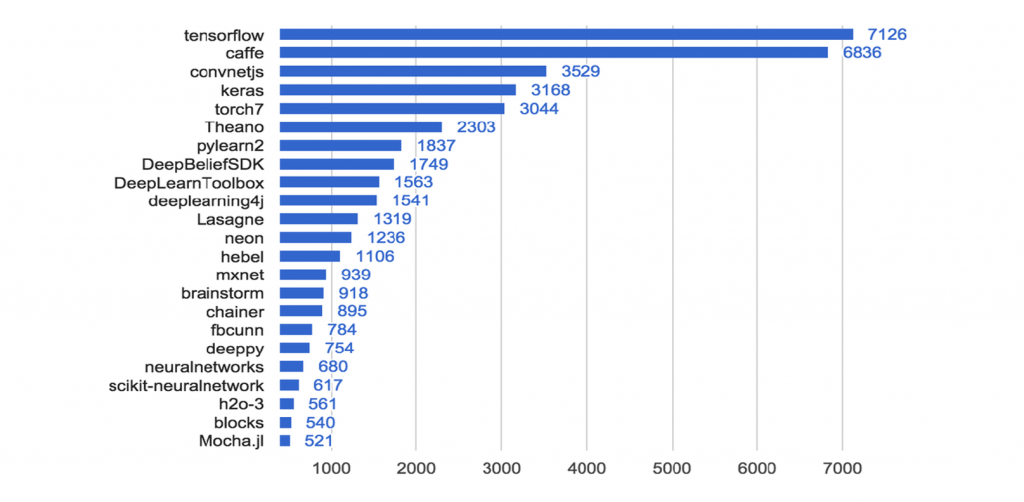
در شکل زیر ابزارهای مختلف برای یادگیری ژرف به همراه تعداد پروژههایی که در آنها از این ابزارها استفاده شده است، مشاهده میشود.
با توجه به تجربه شخصی من در استفاده از تعدادی از این ابزارها در پروژههای گوناگون، پیشنهاد من در مرحله اول استفاده از «تنسورفلو» یا «کراس» و در مرحله بعد استفاده از «پایتورچ» است. همچنین، بهترین منبع برای یادگیری تنسورفلو همان وبسایت رسمی این ابزار است. (وبسایت رسمی تنسورفلو)
سختافزار مناسب
یکی از پرسشهایی که همیشه دانشجویان از من میپرسند این است که حداقل سختافزار مورد نیاز برای این که بتوان در حوزه یادگیری ژرف پژوهش نمود و پروژه انجام داد، چیست؟ پاسخ به این پرسش به عوامل متعددی همانند نوع دادهها (ویدیو، تصویر، متن و غیره)، حجم دادهها، معماری الگوریتم یادگیری ژرف و غیره بستگی دارد. مهمترین عامل که در هنگام تهیه یک سختافزار مناسب باید به آن توجه کنید، پردازشگر گرافیکی میباشد.
پردازشگر گرافیکی
از پردازشگرهای گرافیکی در صنعت بازیهای رایانهای و برای انجام ریاضیات ماتریسی مورد نیاز برای رندر کردن تصاویر گرافیکی استفاده میشود. خوشبختانه، این نوع محاسبات، دقیقا همان محاسباتی است که که در یادگیری ژرف به آن نیاز داریم. پیشرفتهای چشمگیر اخیر در فناوری پردازشگرهای گرافیکی یکی از مهمترین عوامل موفقیت و قدرتمندی شبکههای عصبی در این روزها نسبت به دهههای قبل است. آموزش یک مدل مبتنی بر یادگیری ژرف بدون استفاده از پردازشگرهای گرافیکی قدرتمند، در اغلب موارد بسیار کند و زمانبر است.

پشنهادات
- یک پردازشگر گرافیکی مناسب برای کار کردن در حوزههای متفاوت قیمتی در حدود سه تا چهار میلیون تومان دارد. همچنین حجم حافظه پردازشگر گرافیکی نیز بسیار مهم است.
- تا آنجا که برایتان امکان دارد، سعی کنید یک پردازشگر گرافیکی با بیشترین حافظه گرافیکی (۸ تا ۱۲ گیگا بایت) تهیه کنید.
- همچنین به منظور استفاده از تنسورفلو و سایر ابزارهای مبتنی بر تنسورفلو (همانند کراس و تیانو)، دقت کنید پردازشگرهای گرافیکی انویدیا را تهیه نمایید.

اگر به هر دلیلی به یک پردازشگر گرافیکی قدرتمند انویدیا دسترسی ندارید، میتوانید از طریق ایجاد یک حساب در سرویس وب آمازون (AWS)، از راه دور به پردازشگرهای گرافیکی مورد نیاز خود دسترسی داشته باشید.
در این صورت پیشنهاد میکنم از نمونه g2.2xlarge استفاده کنید. این نمونه هم به اندازه کافی برای اغلب کاربردها قدرتمند است و هم هزینه بسیار پایینی دارد. این هزینه در حدود ۹۰ سنت یا ۴۰۰ تومان به ازای هر ساعت استفاده است.
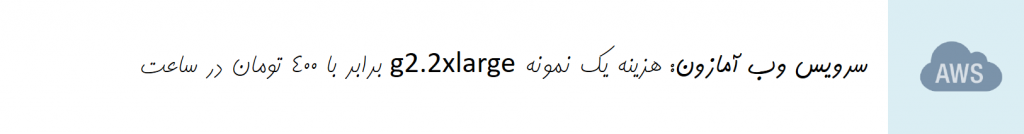
مراجع و منابع
برنامهنویسی و پایتون
- دوره کاربردی برنامهنویسی پایتون با پیادهسازی یک جویشگر متنی (موتور جستجو). سید ناصر رضوی، دانشکده مهندسی برق و کامپیوتر دانشگاه تبریز (زمستان ۱۳۹۵)
- کتاب «پایتون برای تحلیل دادهها»؛ ویراست دوم (۲۰۱۷). مطالعه این کتاب برای یادگیری پایتون، به ویژه با هدف برنامهنویسی در حوزههای یادگیری ماشین، به شدت توصیه میگردد.
یادگیری ماشین
- یادگیری ماشین؛ سید ناصر رضوی؛ دانشکده مهندسی برق و کامپیوتر دانشگاه تبریز (پاییز ۱۳۹۶)
- کارگاه یادگیری ماشین با پایتون؛ سید ناصر رضوی، دانشکده مهندسی برق و کامپیوتر دانشگاه تبریز (پاییز ۱۳۹۶)
یادگیری عمیق
- آشنایی با یادگیری ژرف؛ سخنرانی به مناسبت هفته پژوهش در دانشگاه تبریز (۱۱ آذر ۹۶)
- درس شبکههای عصبی کانولوشنال برای برای بازشناسی بصری؛ دانشگاه استنفورد، بهار ۲۰۱۷
- دوره پاییزه یادگیری عمیق؛ سید ناصر رضوی، پژوهشگاه ارتباطات و فناوری اطلاعات، پاییز ۱۳۹۶
- کتاب آنلاین یادگیری عمیق؛ یان گودفلو و یاشوا بنجیو، انتشارات امآیتی، ۲۰۱۶
- کتاب آنلاین شبکههای عصبی و یادگیری عمیق؛ نیلسن، ۲۰۱۷

{kind=link}
{kind=link}
7 ديدگاه
سلام
به نظرم گزینهٔ بهتر از AWS سامانهٔ ابری floydhub میباشد که هزینهٔ بسیار کمتری دارد.
با سپاس
با درود و سپاس از پیشنهادتون. بسیار لطف میکنید اگر لینکی یا آموزشی از نحوه استفاده دارید در اختیار بنده قرار بدید تا اون رو هم معرفی کنم. چون دسترسی به سختافزار مناسب الان یکی از مهمترین موانع برای افراد بسیاری هست.
سلام
به عنوان شخصی که در سیستم آکادمیک هستید چه قدر خوب بود وقتی از مطالب و شکل و … دیگران و درس های خارجی استفاده میکردید ( گرچه ترجمه به فارسی کردید) حداقل در آخر ارجاعاتی به آنها میدادید.
با درود بله حتما این کار انجام خواهد شد. بالای نوشته هم عرض کردم که این نوشته ناقص و در حال ویرایش است. ممنون از حساسیت به جای جنابعالی.
باسلام
سوالی که پیش میاید اینکه نرو نهای عصبی در سلولها انواع تشخیص در مورد دما ،احساس درد،تشخیص بو،دریافت علائم خطر و….و مهمتر از همه انتقال دریافته هادر این زمینه هاست که البته به چند نوع مختلف توضیح داده شده در ویدیو هاست ایا میتوان خطرات را از طریق یاداوری ماشین وایجادکلاسها شناسانی کرد؟ اینکه ماشین قبل از اتفاق افتادن یاد اوری کند؟.باتشکر از زحماتتون.
با سلام
ویدئو های یوتیوب واقعا از نظر کمی و کیفی عالی هستن واینکه امکان مطرح نمودن سوال در کلاس بیشتر باشه و ویدیو های کلاسهای اخیر منتشر میشوند از زحماتتون بینهایت تشکر میکنم. .
با سلام
از مطالب ارزشمند شما بسیار متشکرم. سوال بنده در رابطه با مسائلی است که در آن قرار است رخدادی در آینده با توجه به روند گذشته آن پیشگویی شود. به عنوان مثال با استفداه از داده های مربوط به هواشناسی سالهای قبل میخوایم تخمینی از میزان بارندگی در سالهای پیش رو را داشته باشیم. آیا چنین امری با استفاده از یادگیری ژرف میسر است؟ اگر چنین است کدام گونه یادگیری باید بکار گرفته شود؟
بی صبرانه منتظر پاسخ و راهنمایی های ارزشمند شما خواهم ماند
با سپاس فراوان